

近日,一个由斯坦福学生组成的AI团队,发布了一个多模态大模型获得大量关注。但随后,该模型被指抄袭,因其与国内清华系大模型相似度极高。
目前,该斯坦福团队已公开道歉,并删除了相关库和宣传推文。
An artificial intelligence (AI) team at Stanford University apologized for plagiarizing a large language model (LLM) from a Chinese AI company, which became a trending topic on the Chinese social media platforms, where it sparked concern among netizens on Tuesday.
斯坦福AI团队被指抄袭,成员公开道歉
斯坦福大学AI团队在5月29日发布了一个名为Llama3-V的多模态大模型,声称只需500美元就能训练出一个性能可与GPT4-V媲美的模型。Llama3-V不仅在社交媒体上迅速蹿红,还一度冲上了HuggingFace趋势榜首页。
The apology came after the team from Stanford University announced Llama3-V on May 29, claiming it had comparable performance to GPT4-V and other models with the capability to train for less than $500.

图源:X
然而,有网友发现,该团队发布的Llama3-V和国内大模型MiniCPM-Llama3-V 2.5有极高的相似度,后者是由国内大模型初创企业“面壁智能”和清华大学自然语言处理实验室联合推出的。
However, some netizens from X found and listed evidence of how the Llama3-V project code was reformatted and similar to MiniCPM-Llama3-V 2.5, an LLM developed by a Chinese technology company, ModelBest, and Tsinghua University.
网友还在面壁智能GitHub的项目下放出了一系列证据,如这两个模型的结构、代码、配置文件都一模一样,只有变量名被替换了。
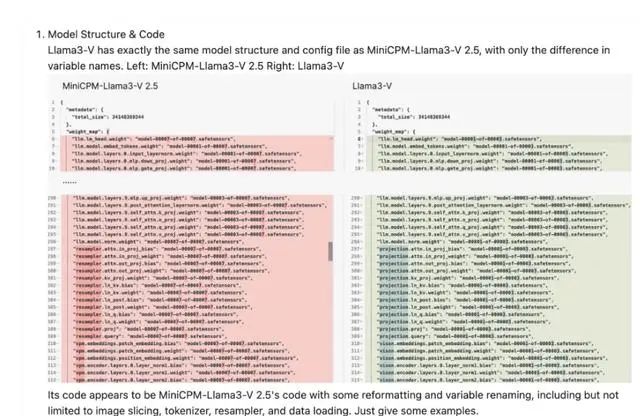
两个模型的代码对比 图源:GitHub
随后,面壁智能首席科学家、清华大学长聘副教授刘知远在知乎上回应,MiniCPM-Llama3-V 2.5在研发时内置了一个彩蛋,就是对“清华简”的识别能力,而Llama3-V模型居然也有一模一样的能力。
Both Llama3-V and the MiniCPM-Llama3-V 2.5 large model are based on the open-source Llama3 large model. Still, the team in Tsinghua conducted unique training, including using the "Tsinghua Bamboo Slips," a collection of Chinese texts written on strips of bamboo which date back to the Warring States Period (475-221 BC), to train the model to recognize ancient Chinese characters.
Tests show that the model released by the Stanford University team can also recognize the "Tsinghua Bamboo Slips."
清华简是清华大学于2008年7月收藏的一批战国竹简,为战国中晚期文物。刘知远透露,识别清华简是MiniCPM-Llama3-V 2.5的一项实验功能,训练图像是最近从出土文物中扫描并标注,且尚未公开发布。
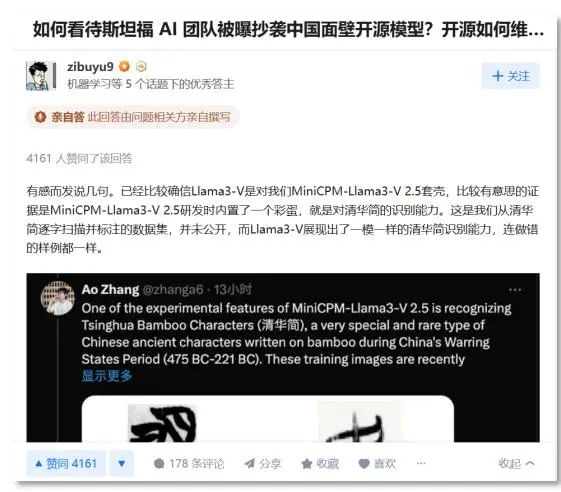
而两个模型在识别的表现上,正确的结果上基本一致,错误的情况也颇为相似。
"We are quite sure that the Stanford team has plagiarized our big model research results," Liu Zhiyuan, a tenured associate professor of the Department of Computer Science at Tsinghua University, told Xinhua.
"The data we scanned and annotated word by word from the 'Tsinghua Bamboo Slips' has never been made public, and Llama3-V has shown the same ability to identify the 'Tsinghua Bamboo Slips,' even the error examples are the same," said Liu, who is also a member of the Tsinghua big model team.
遭到大量质疑后,该斯坦福团队成员已删除他们在X上官宣模型的推文,并将该项目在Github和HuggingFace上的库一并删除。
As doubt accumulated, the Stanford team deleted the database and promotion articles on the Internet, Liu said, adding "from the evidence and their reactions, the nature of plagiarism has been relatively confirmed."
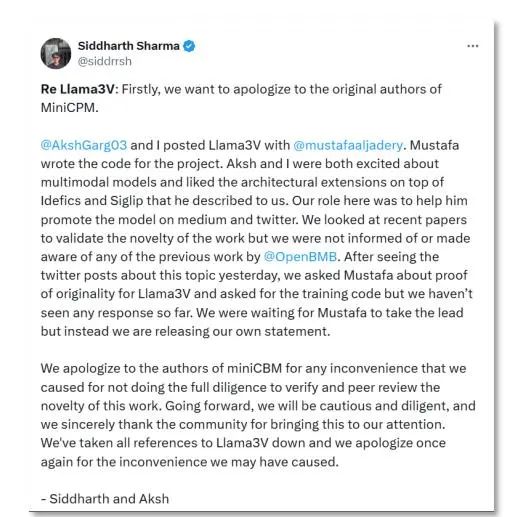
最新消息,4日,斯坦福Llama3-V团队的两位作者森德哈斯·沙玛(Siddharth Sharma)和阿克沙·加格(Aksh Garg)在社交平台上就这一学术不端行为向面壁MiniCPM团队正式道歉,并表示会将Llama3-V模型悉数撤下。
图源:X
沙玛表示,“首先,我们要向MiniCPM原作者道歉。我、阿克沙,以及穆斯塔法一起发布了Llama3-V,穆斯塔法为这个项目编写了代码,但从昨天起就无法联系他。我与森德哈斯·沙玛主要负责帮助穆斯塔法进行模型推广。我们俩查看了最新的论文,以验证这项工作的新颖性,但并未被告知或意识到OpenBMB(清华团队支持发起的大规模预训练语言模型库与相关工具)之前的任何工作。我们向作者道歉,并对自己没有努力验证这项工作的原创性感到失望。我们对所发生的事情承担全部责任,并已撤下Llama3-V,再次致歉。”
Two team members, Aksh Garg and Siddharth Sharma, reposted a netizen's query and apologized on Monday, while claiming that their role was to promote the model on Medium and X (formerly Twitter), and that they had been unable to contact the member who wrote the code for the project.
They looked at recent papers to validate the novelty of the work but had not been informed of or were aware of any of the work by Open Lab for Big Model Base, which was founded by the Natural Language Processing Lab at Tsinghua University and ModelBest, according to their responses. They noted that they have taken all references to Llama3-V down in respect to the original work.
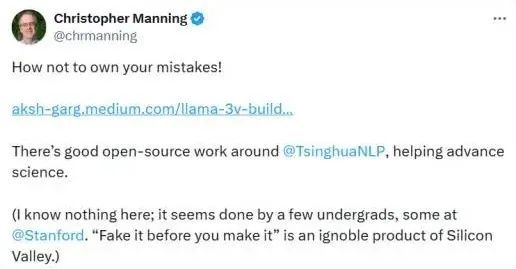
此外,斯坦福人工智能实验室主任克里斯托弗·大卫·曼宁(Christopher David Manning)也发文谴责这一抄袭行为。
图源:X
Director of the Stanford Artificial Intelligence Laboratory Christopher Manning also responded to Garg's explanation on Sunday, commenting "How not to own your mistakes!" on X.
据媒体报道,6月3日,面壁智能CEO李大海也对此做出回应,他表示,“技术创新不易,每一项工作都是团队夜以继日的奋斗结果,也是以有限算力对全世界技术进步与创新发展作出的真诚奉献。我们希望团队的好工作被更多人关注与认可,但不是以这种方式。我们对这件事深表遗憾!一方面感概这也是一种受到国际团队认可的方式,另一方面也呼吁大家共建开放、合作、有信任的社区环境。一起加油合作,让世界因AGI的到来变得更好!”

According to a screenshot leaked online, Li Dahai, CEO of ModelBest, also made a post on his WeChat moment, saying that the two models were verified to have highly similarity in terms of providing answers and even the same errors, and that some relevant data had not yet been released to the public.
He said the team hopes that their work will receive more attention and recognition, but not in this way. He also called for an open, cooperative and trusting community environment.
赞一个
- 文章标签:
- 高校动态


更有众多热门




